Workload Identity Federation for CI/CD on GCP
A better way to authenticate service accounts
Many cloud solutions rely on static credentials when performing automated processes. Automation is necessary in many technical projects - whether cloud engineering, software development, or data and machine learning - and plain old user accounts cannot help with this.
The major cloud platforms have different ways to deal with this, but they generally follow similar patterns:
- Static credentials in a key file
- Access keys - either a single key or client ID/client secret pair
- Managed or federated identities.
This post will focus on GCP.
Service account keys
In GCP, service accounts are created from a screen in the IAM service of the platform. I’ve redacted the names here, but they follow the convention of service-account-name@gcp-project.iam.gserviceaccount.com.
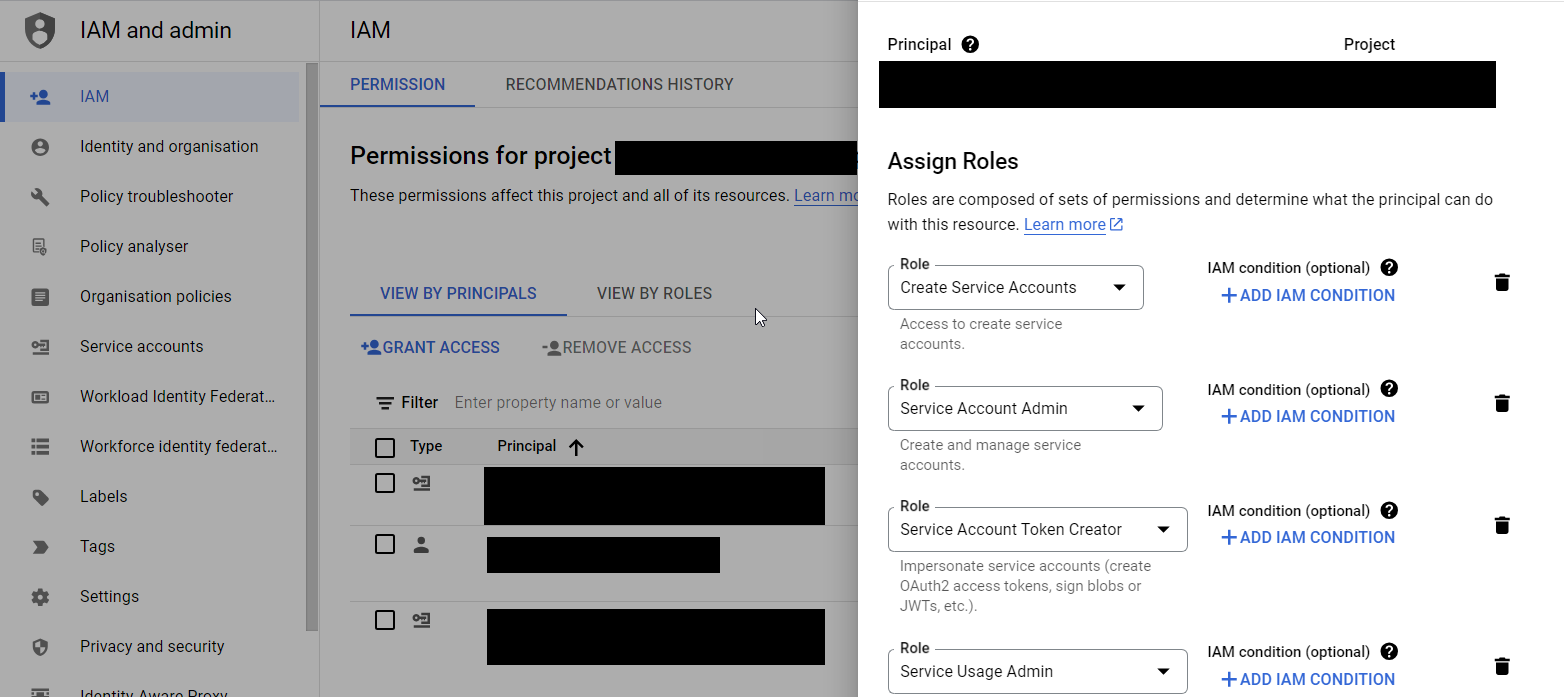
These can be assigned any IAM roles just like a user account.
The most common way of using these service accounts is through physically downloading a key, in JSON format, for that specific service account. This can be used in a couple of ways:
- Service account impersonation on your PC by saving it as your application default credentials
- Using the credentials to perform automated actions
Across many companies in Australia, I have seen this pattern used. In fact, the continuous deployment pipeline for this blog used service account keys when it was still a Django app deployed to Cloud Run.
This is an abbreviated version - the full pipeline can be seen here.
They are useful and a valid way of activating a service account, but human error can lead to breaches. We are not that far removed from an incident regarding Okta and improperly-handled service account credentials, and the story of developers saving secrets in a Github repository are a meme at this stage.
Thankfully, there is a more secure way.
Introducing workload identity federation
Workload identity federation was released in April 2021.
The service essentially allows keyless authentication. A workload identity “pool” is set up to manage identities coming from external sources that may normally require a service account key. Each pool can have many “providers”. These are resources that describe a relationship between GCP and the external source.
These relationships are set up using OpenID Connect (OIDC) to verify an external source’s right to access GCP resources. There are a few steps:
- Set up the workload identity pool
- Add a provider for Github Actions and set up custom attribute mappings
- Give the service account the correct permissions in IAM
- Authenticate in your deployment pipelines
All of my examples are created using OpenTofu, the new free and open source fork of Terraform. As of this writing, these steps should also work for Terraform, but expect the two projects to diverge over time.
Workload identity pool
The Tofu code for this part is fairly straightforward. The pool just needs names and IDs to refer to later.
Workload identity provider
This is where things get a little bit more complicated. Two configuration items are required:
- An identifying URL for the service that GCP should expect to receive OIDC tokens from
- Nothing is sent to this URL by GCP. Github will identify itself with this URL, and we configure GCP to expect this
- A set of attribute mappings that can translate items in the Github OIDC token into terms that the workload identity federation service can understand.
I followed GCP recommendations here, so the following attributes need to be set up:
| GCP attribute | Github attribute | Description |
|---|---|---|
google.subject |
assertion.sub |
The object in Github related to this request. In our case, a repository |
attribute.repository_id |
assertion.repository_id |
The ID of your repository |
attribute.repository_owner_id |
assertion.repository_owner_id |
The ID of your Github account |
Finally, a CEL expression must be written for attribute conditions. This looks something like this:
assertion.repository_id=='1234' && assertion.repository_owner_id=='5678'
This is what makes the repository ID and owner ID mappings important: without the condition above, GCP would accept any workload identity request from any Github Actions pipeline, including those you didn’t create.
Github sends a lot of different attributes that can be mapped, but I’ve followed the recommended ones. Repository and owner names are accepted, but they can open you up to cybersquatting if you delete your Github account, forget to delete the identity pool, and someone creates a new account with your old name.
Either way, the Tofu code looks like this:
Service account permissions
The service account must be set up with the necessary permissions to handle resources required by the pipeline. In my example, I’m just turning on service APIs for this project, so there’s not much to look at - you already saw an example of the permissions required in an earlier screenshot.
Note that for my projects, I provision a service account for infrastructure provisioning myself. I do not use Tofu to create it, but I do give it IAM roles.
In addition to service permissions, the target service account must also be given workload identity permissions. These map a service account to the identity pool created earlier.
Note that the member is a special “principal set”, not your usual service account or user ID. This URL maps the service account to the workload identity pool. I have also added the extra repository ID attribute to this URL, to further harden my workload identity pool. I never figured out how to add both repository ID and repository owner ID to this and get it to work, but the attribute conditions from an earlier step should keep this locked down nicely.
Deployment
Over to the pipelines - in my case I’ve got a Tofu deployment pipeline.
There are a few things to note:
- I have specified secrets to hide names of projects and GCP services.
- The
permissionsblock tells Github straight away that an OIDC token needs to be created. - The
gcp_workload_providerenvironment variable follows the formatprojects/PROJECT_NUMBER/locations/global/workloadIdentityPools/POOL_ID/providers/PROVIDER_ID
Your project number can be retrieved from the front page of the Google Cloud console. The pool and provider IDs are the names given to these services at creation time. In my case, I’ve also needed to add /attribute.repository_id/GITHUB_REPO_ID as described in the previous step.
Finally, the authentication step usually present in Github Actions pipelines needs to contain the workload_identity_provider variable instead of specifying a key in json_credentials.
Wrapping up
I hope this has been helpful. While it can be convenient to use service account keys, consider workload identity federation in your deployment pipelines. Please keep in mind they are not infallible. Tenable has a good article on how this solution can still be exploited - mostly configuration errors such as defaults or incorrect permissions leading to a larger blast radius. Keep in mind and always double check your configurations!
Thanks for reading.