Apache Iceberg on GCP
Is lakehouse in all our futures?
I like the lakehouse concept.
I have primarily worked with BigQuery in cloud-native data stacks. Despite this, my journey from a C# developer moonlighting as a business intelligence guy to becoming a cloud data engineer mostly started with the discovery of Databricks on Azure in 2018.
Databricks is one of the leading cloud data vendors out there, packaging up cloud-managed Apache Spark with a notebook interface plus governance and machine learning platforms. This is all underpinned by Delta Lake, an “open table format” that adds database-like features on top of cloud object storage.
Databricks has lead the way, but new formats with the same idea have begun to emerge. The Netflix-developed Apache Iceberg is the frontrunner of these new formats, with some even going so far as to say it “won” the table format war. Whether you agree with that or not, people have started to take notice of alternatives to Delta.
This has become enough of a big deal that both cloud data warehouses Snowflake and BigQuery support it. We’ll cover the BigQuery support in this post.
Enter BigLake
BigLake is Google’s storage engine that adds support for running queries over more complex object storage formats from their BigQuery data warehouse. Prior to Iceberg, BigLake supported common formats like Parquet, Avro, CSV and JSON. These formats were always supported via BigQuery’s external table functionality, but BigLake adds additional governance, support for multiple query engines, and even cross-cloud tables. More details here.
Testing BigLake Out
I’ll focus on Apache Spark here, as it was my first “big data”, parallel-processing framework and the one that most Iceberg tutorials are written for.
In GCP, BigLake functions as a drop-in replacement for a Hive Metastore. Even though Spark has evolved far beyond its Hadoop roots, a metastore is still an essential part of any stack involving Spark (including Databricks, who manage a metastore for you).
I started with a simple enough example. The team at Risk Thinking have a public data engineer assessment project for their interview candidates. This served as quick inspiration for a dataset to use - I originally planned to do the entire project for fun, but haven’t prioritised it.
Google’s examples for BigLake, at the time I did this, were really pointing towards using Serverless Spark for BigQuery Stored Procedures, but I opted to start with a Dataproc cluster so it was easier for me to troubleshoot before moving to a serverless option.
I will purely cover the Dataproc serverless option with all the pain-points resolved so that you don’t have to worry about it!
Getting Started
You will need a Google Cloud project for this. First, enable the following APIs in Google Cloud:
I’ve provided links, but you may need the right project selected to open them properly. If these links aren’t helping, search for them by typing “biglake”, “dataproc” and “bigquery connection” into your GCP search bar:
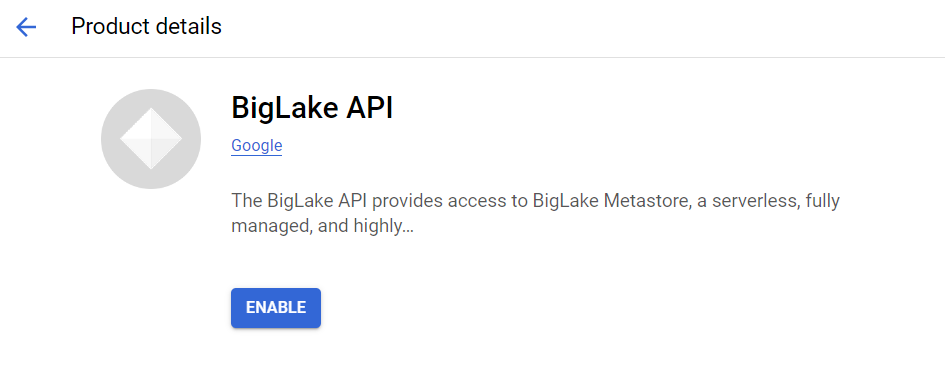
At this time, BigLake and its metastore capabilities do not have their own user interface. You turn on the API, and you’re good to go, with metastore-managed tables appearing in BigQuery if you set up the proper connections.
Dataproc is GCP’s managed Spark service. It supports both managed cluster and serverless options.
Next, Private Google Access on a VPC subnet is required for Dataproc Serverless to run. In my example, I’m just applying it to the default subnet.
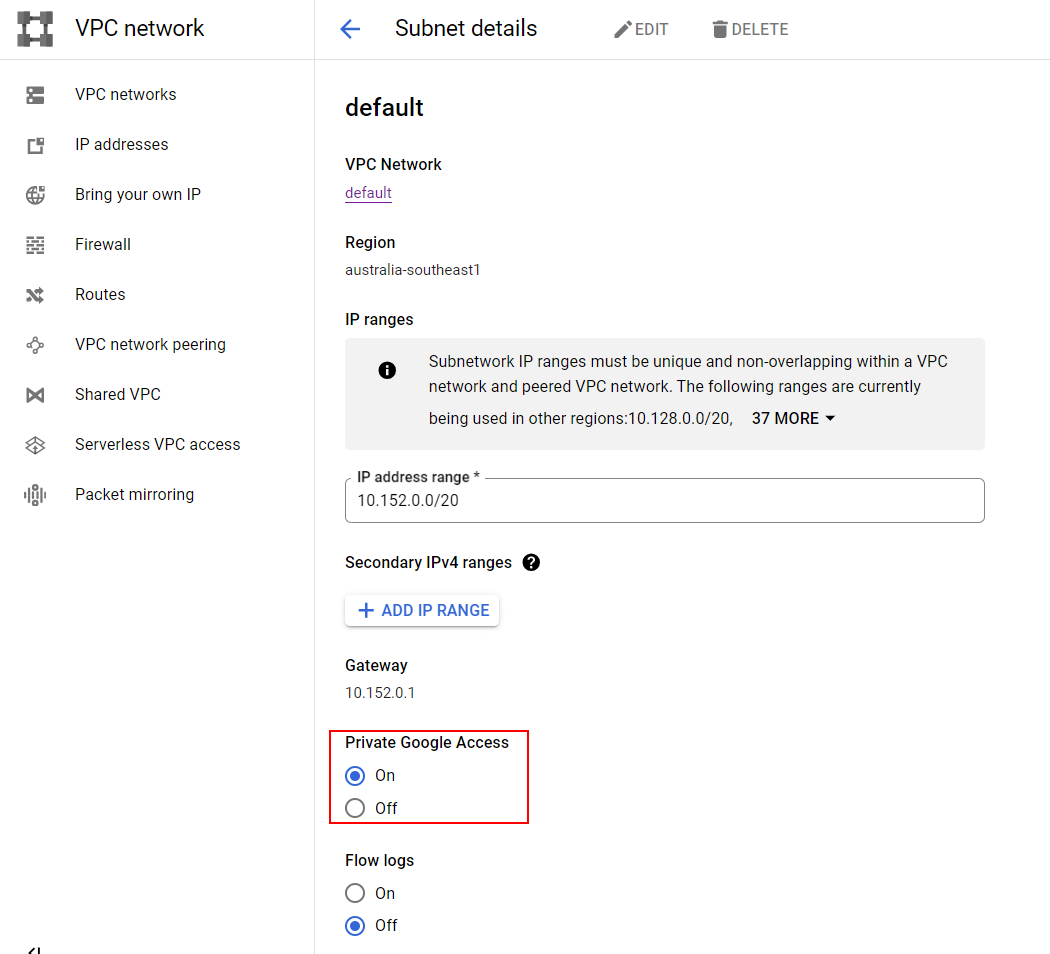
Be aware that this is open up to the world, and Google recommends using network tags and firewall rules to limit it to the subnet you’re using (in my case, the default one in australia-southeast1). More information here.
Next, go to BigQuery, and:
- Create a dataset (I named it
nasdaq) - Create an external connection to BigLake.
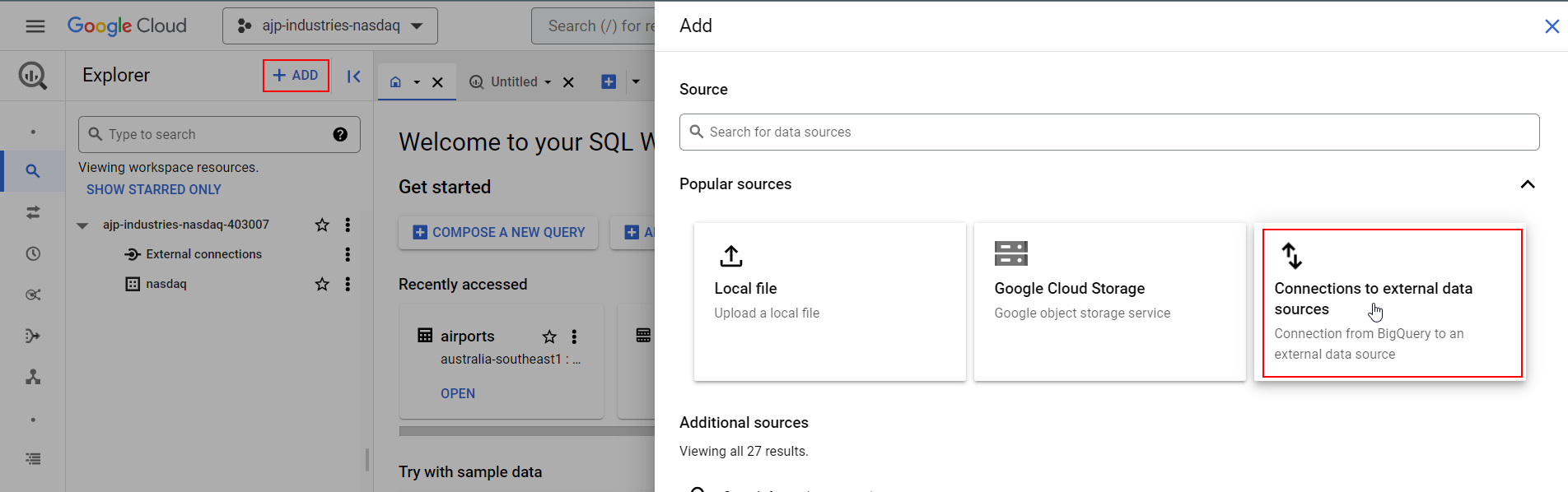

Finally, create a service account with the following roles:
- BigLake admin (sic) globally - in Google’s demos this reads “BigLake Admin”, but not in GCP currently?
- Dataproc Worker globally
- BigQuery Connection Admin on the external connection you just set up
- BigQuery Data Owner globally
- BigQuery Job User globally
In an ideal world, I would tweak the BigQuery roles to not apply globally, but on specific datasets that the Iceberg tables will be created in. But this is a blog example with a lot of moving parts, so I’m leaving some of this as an exercise for the reader.
In place of BigQuery Connection Admin, I would create a custom role that has the bigquery.connections.delegate role. Only Admin has it out of the box.
Running on Dataproc Serverless
Dataproc distinguishes between jobs on a cluster and batches on serverless compute. This is reflected in the Google Cloud CLI commands used to submit workloads to the right place.
The repository for this example can be found on my Github account. It’s in its own branch for now and the code isn’t “production grade”, but works well enough for this basic example. In the data folder is the raw data used for the example. You can upload this to a storage bucket before running the example code.
The setup_iceberg script creates a BigLake metastore and tables for the processed data. Note the TBLPROPERTIES section where it references the external connection and dataset previously created in BigQuery. This will let Spark, BigLake and BigQuery talk to each other and create the tables automatically.
The ingest_stock script reads data stored in a storage bucket and writes it to the Iceberg tables with Spark. In this example, an ingest_etf script could also be made - just copy the script below and update the relevant references.
Both scripts are run in the same fashion - let’s use ingest_stock as an example:
A few notes:
-
Even though the code specifies many configuration properties, the target JAR file must be specified in the
--propertiesCLI argument -
The batch name, if specified by the
--batchCLI argument, must be unique. If you’ve run a batch with this name before, you will get an error. If a batch name is not specified, GCP will generate a random UUID for it, but this might make it hard to identify jobs. I’d suggest making a name for the batch and appending a UUID to it if running this in an automated fashion. -
If you’re attempting this on Windows, I suggest using the Google Cloud Shell to run the shell script. The Dataproc CLI attempts to add a folder called
dependenciesto the bucket specified in thedeps-bucketargument. When running on Windows, this tries to add the folder incorrectly - if the bucket URL isgs://example_bucket, it will try to creategs://example_bucket\dependencies, not/dependencies, which will cause an error. At time of writing, my only successful attempt was using Cloud Shell. Git Bash and WSL, although pretty good at simulating Unix terminals on Windows, have the same problem.
Moving to BigQuery
Once this has all been run, the destination bucket will have a folder created for the Iceberg catalog, the data you write to it, and metadata that makes all of Iceberg’s magic possible.
If we go straight over to BigQuery, we’ll see all the tables and their data. These will be external tables with the source URIs pointing at our metastore!
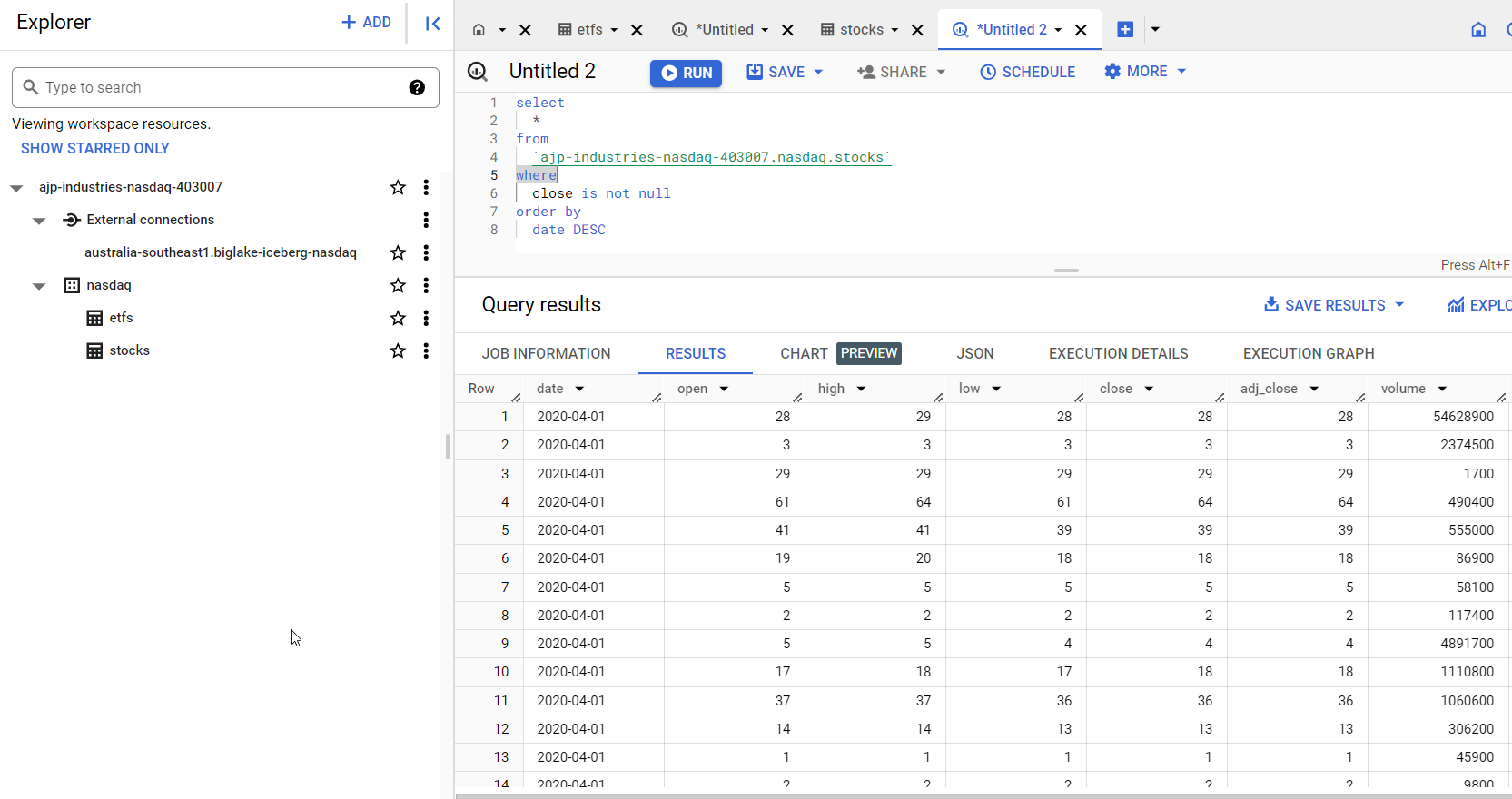
But that prompts the question…
Dude, Where’s My Metastore?
Unfortunately at time of writing there seems to be no way to visually see the metastore created by Spark in the setup_iceberg script. Google’s documentation still shows the only methods of seeing it as using Spark or a BigLake API call. If all goes well, this might be satisfactory just seeing the resulting tables in BigQuery. For people who are used to a Databricks-like experience this might be a bit disappointing.
I have seen that Terraform has support for BigLake catalogs though, so at least there’s a way of knowing for sure that your metastore exists. I didn’t play with the Terraform resource for this, but assume it uses the BigLake API instead of a Spark job.
Ending The Experiment
Ultimately, this is where I stopped the experiment. Although I love playing with new tech, I stopped for a few reasons:
-
I have a lot of other projects to complete and blog about
-
This took a LOT of effort to set up. Part of the reason people use Google Cloud for analytics is you can sign up, open the GCP UI, click on BigQuery, and… you’re ready to go.
-
Differences in complexity aside, I am still convinced at this stage that continuing with native tables in BigQuery is still the “right way” of doing data and analytics in GCP
-
If I really wanted a Spark experience, I think I would still use Databricks as a one-stop-shop solution.
I hope this was still useful in navigating the eccentricities of a BigLake setup. This work was originally done in August and took me a weekend’s worth of diving through documentation and errors to get running. When I picked it up yesterday to jog my memory and write this blog, I still had to make adjustments to my workflow to get it working again.
There is also an alternative to all of this using BigSpark - serverless Spark running in BigQuery stored procedures. I opted to not use this as it was a lot of code to write purely in the BigQuery UI, but Google has a video of this approach here.
It’s hard to say where things will go in future. Google has been putting energy into BigFrames for people who might prefer code-driven pipelines instead of pure SQL, but since I did this experiment, BigLake support for Hudi and Delta were announced, so maybe it’s always going to be a choose-your-own-adventure. I think I’ll hang on to BigQuery native tables until it’s no longer an option.
Thanks for reading.